Machine Learning - I
03 Apr 2017
Computers which can think like humans or intelligent life, robots who can automatically search for objects as humans or animals do! Woah all this sounds like a scene out of the sci-fi movies like Minority Report. Autonomous cars and what not are all results of the recently emerging field of machine learning.
If you consider the past 7-8 years, ML has garnered serious attention from academia and industries alike. There is a very strong rationale behind revolutionizing our century (or maybe decade: P) old technologies ranging from healthcare to travel.
If one needs to understand ML through its scientific explanation, here you go:
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”
Very academic for the lay mind? This post aims to address the issue of making machine learning easily understandable by anyone wanting to learning about it.
Because ML is a field which already has got countless API(application programming interfaces) which can be used without understanding the mathematical logic running the learning algorithms, but if you also possess this skill set your journey into ML will be much more smooth and clear.
What is Machine Learning?
At the ground level, machine learning is not at all a difficult concept to catch. Most ML algorithms involve the rudimentary task of drawing lines (but through data).
By drawing lines, it doesn’t only mean creating a line using a Paint job, but using these lines(straight, curves, zig-zag almost anything) for separating or classifying data based on related parameters.
Better to understand this through examples!
Classification
Let’s consider a hypothetical experiment. You have got a bag full of 3 different types of toys:
- Toy X (a red coloured ball)
- Toy Y (a square shaped Rubix Cube)
- Toy Z (a doll)
Now if I tell you to separate all the toys into different groups, how would you do it? Think about even the most basic steps involved in doing this task.
- You have an image of a ball, a rubix cube and a doll in your brain from an earlier experience
- Using your past experience you know, how a ball is spherical in shape and how the color red would appear on ball, and so you create a mental image of the same for all the toys involved
- Now one by one you pick up the toy and identify it as Toy x, y or z based on how closely it matches your mental image
- Once all the 20 toys have been identified as being either once of the 3 categories(x, y and z), you place them into separate groups
- So in machine learning terms, you have accomplished the task of object classification
Cheers to you!
Now just for a moment consider how the same task can be accomplished by a robot?
Quit complex right?
Now lets imagine from the point of view of a computer, which has images of oranges (orange colour) and guavas(green colour) of different sizes. Most machine learning algorithms begin by first getting your hands on labeled training data to feed to our model.
For our case, we would require a large number of images of guavas and oranges of various sizes which are labelled according to their type. So now if we plot our collected images, we might get a graph like this:
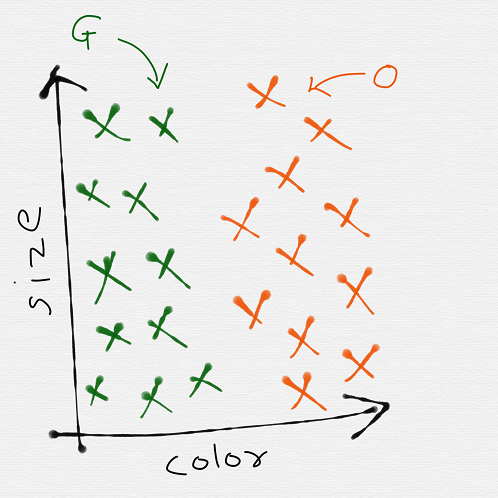
Here the green x’s are guavas and the orange x’s are well oranges. As it can be easily noticed from the graph, there is an underlying pattern.
All the oranges seem to group on the right side of our plot while the guavas are all placed on the left side. Much as we humans can infer these patterns through observations, computers can learn the same using algorithms.
Now for separating the two fruits, we require to develop a algorithm which segregates them using a simple line in between. This line can be called the decision boundary.
So if we are considering the simplest decision boundary, our graph would appear as:
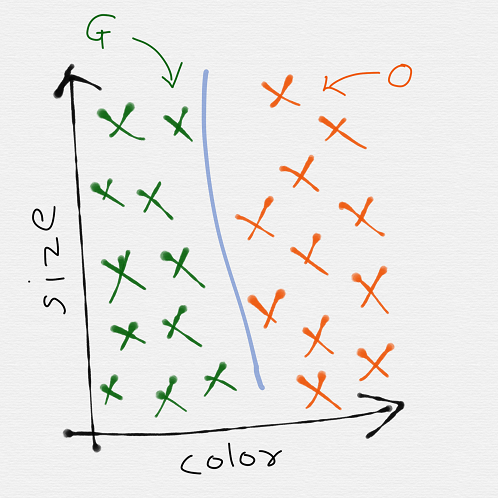
You might say this is just a straight line, and what if we have a more mixed shapes of fruits which can’t be separated using straight lines?
No issue at all! Simply increase the complexity of your learning algorithm and you might end up getting a more non-linear boundary:
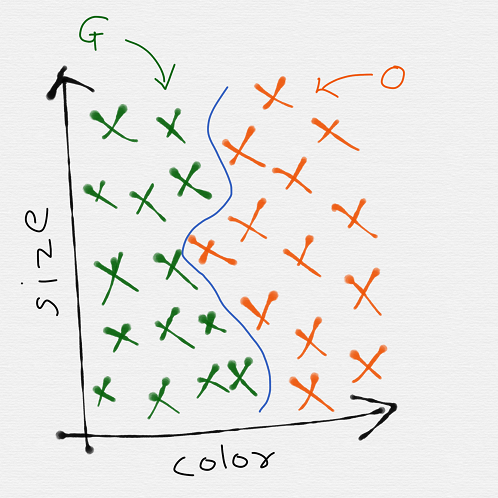
While our algorithm does a good job at classifying the set of fruit images we give it into the 2 categories, we are assuming that the same will work for any image. Also it needs to be considered that as we increase the complexity we are also paving way for overfitting, but more about it later.
So to rephrase it:
Once our algorithm has learnt from the given set of orange and guava images, it has the ability to generalize its experience to images of guava and oranges it hasn’t yet encountered
For instance if we give the algorithm another image of fruit represented by the violet x, based on our decision boundary we could classify it as an orange!
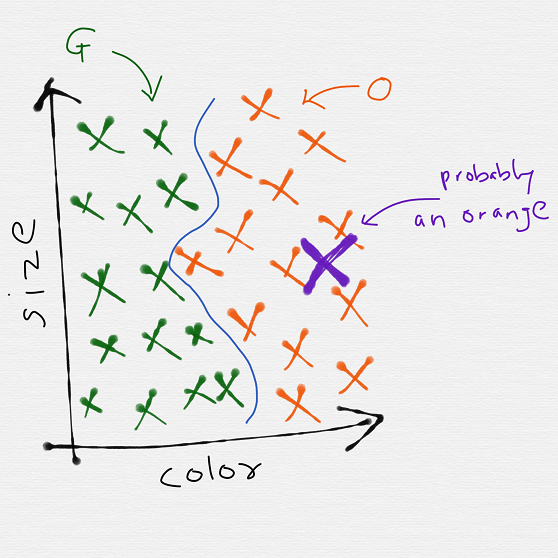
Using this small example, we have now seen the power of machine learning, which uses some training data to generate a decision boundary. And the results of what we have learned are extrapolated to totally new portions data.